
Bronsted Acids and Bronsted Bases
According to Bronsted-Lowry theory of acids and bases,
- an acid is a proton, H3O+ or H+ donor
- a base is a proton, H3O+ or H+ acceptor
The strength of an acid or base is related to the extent of dissociation in solution:
- a strong acid or base is fully dissociated
- a weak acid or base is partially dissociated
So therefore we will have 4 possible types of acids and bases:
1. Weak Acid
2. Strong Acid
3. Weak Base
4. Strong Base
Also, each of these acids and bases will dissociate in solution to give different species.
1. Weak Acid Dissociation eg CH3COOH
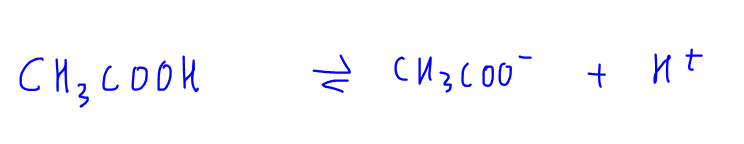
CH3COOH is a weak acid and dissociates partially in solution (as indicated with reversible arrow) to form H+ and CH3COO- ions.
Since this is a reversible process, CH3COO- can accept H+ to form back CH3COOH.
Therefore the nature of CH3COO- is basic and we call CH3COO- the conjugate base of CH3COOH.
2. Strong Acid Dissociation eg HCl

HCl is a strong acid and will dissociate fully (as indicated with full arrow) in solution to form H+ and Cl- ions.
Since this is an irreversible process, Cl- has no tendency to accept H+ and form back HCl.
Therefore the nature of Cl- is neutral.
3. Weak base dissociation eg NH3

NH3 is a weak base and dissociates partially in solution (as indicated with reversible arrow) to form OH- and NH4+ ions.
Since this is a reversible process, NH4+ can donate H+ to form back NH3.
Therefore the nature of NH4+ is acidic and we call NH4+ the conjugate acid of NH3.
4. Strong base dissociation eg NaOH

NaOH is a strong base and will dissociate fully (as indicated with full arrow) in solution to form OH- and Na+ ions.
Since this is an irreversible process, Na+ has no tendency to donate H+ and form back NaOH.
Therefore the nature of Na+ is neutral.
So in summary:
- weak acid will dissociate to give conjugate base
- weak base will dissociate to give conjugate acid
- strong acid will dissociate to give a neutral ion
- strong base will dissociate to give a neutral ion

These concepts are fundamental and very important in Ionic Equilibria.
Check out this video lesson to learn more about acids and bases and their dissociation in solution!
Topic: Ionic Equilibria, Physical Chemistry, JC, H2, A Level Chemistry, Singapore
Back to other previous Physical Chemistry Video Lessons.
Found this A Level Chemistry video useful?
This free chemistry video lesson is brought to you by Chemistry Guru, Singapore's leading JC Chemistry tuition centre since 2010.
Please like this video and share it with your friends!
Join my 19,000 subscribers on my YouTube Channel for new A Level Chemistry video lessons every week.
Check out other A Level Chemistry Video Lessons here!
Need an experienced tutor to make Chemistry simpler for you?
Do consider signing up for my A Level H2 Chemistry Tuition classes at Bishan or online chemistry classes!
